




Extract Knowledge Retrieval's information and Output in Markdown (1/2)
💻 Dify has a Knowledge Retrieval node, but most people don't know how to make the data of it appear at the end of the conversation, in the middle, or elsewhere. Through this Code Node, you can accurately extract them and output them at the appropriate location according to your needs. ☝️ Please note that many people have encountered the "Hallucination" problem, which outputs incorrect information, such as non-existent links. In fact, this is not a problem with Dify, essentially, this is the problem with Large Language Model. If you look carefully at the Knowledge Retrieval node, you will find that it is easy to hit the knowledge base fragment if your configuration is correct (for example, the Enhance / Rewrite Query node in front). 👨💻 At this time, using the Large Language Model to output is equivalent to outputting the URL word by word, and there is a certain error rate at this time; 👉 Conversely, it is better to use Code Node to extract the URL and insert it into the appropriate position using an error-free program. Not only is it fast, but it’s also unmistakable ❤️ This one is for extract. (1/2) Thanks for Claude ❤️
💻 Dify has a Knowledge Retrieval node, but most people don't know how to make the data of it appear at the end of the conversation, in the middle, or elsewhere. Through this Code Node, you can accurately extract them and output them at the appropriate location according to your needs. ☝️ Please note that many people have encountered the "Hallucination" problem, which outputs incorrect information, such as non-existent links. In fact, this is not a problem with Dify, essentially, this is the problem with Large Language Model. If you look carefully at the Knowledge Retrieval node, you will find that it is easy to hit the knowledge base fragment if your configuration is correct (for example, the Enhance / Rewrite Query node in front). 👨💻 At this time, using the Large Language Model to output is equivalent to outputting the URL word by word, and there is a certain error rate at this time; 👉 Conversely, it is better to use Code Node to extract the URL and insert it into the appropriate position using an error-free program. Not only is it fast, but it’s also unmistakable ❤️ This one is for extract. (1/2) Thanks for Claude ❤️
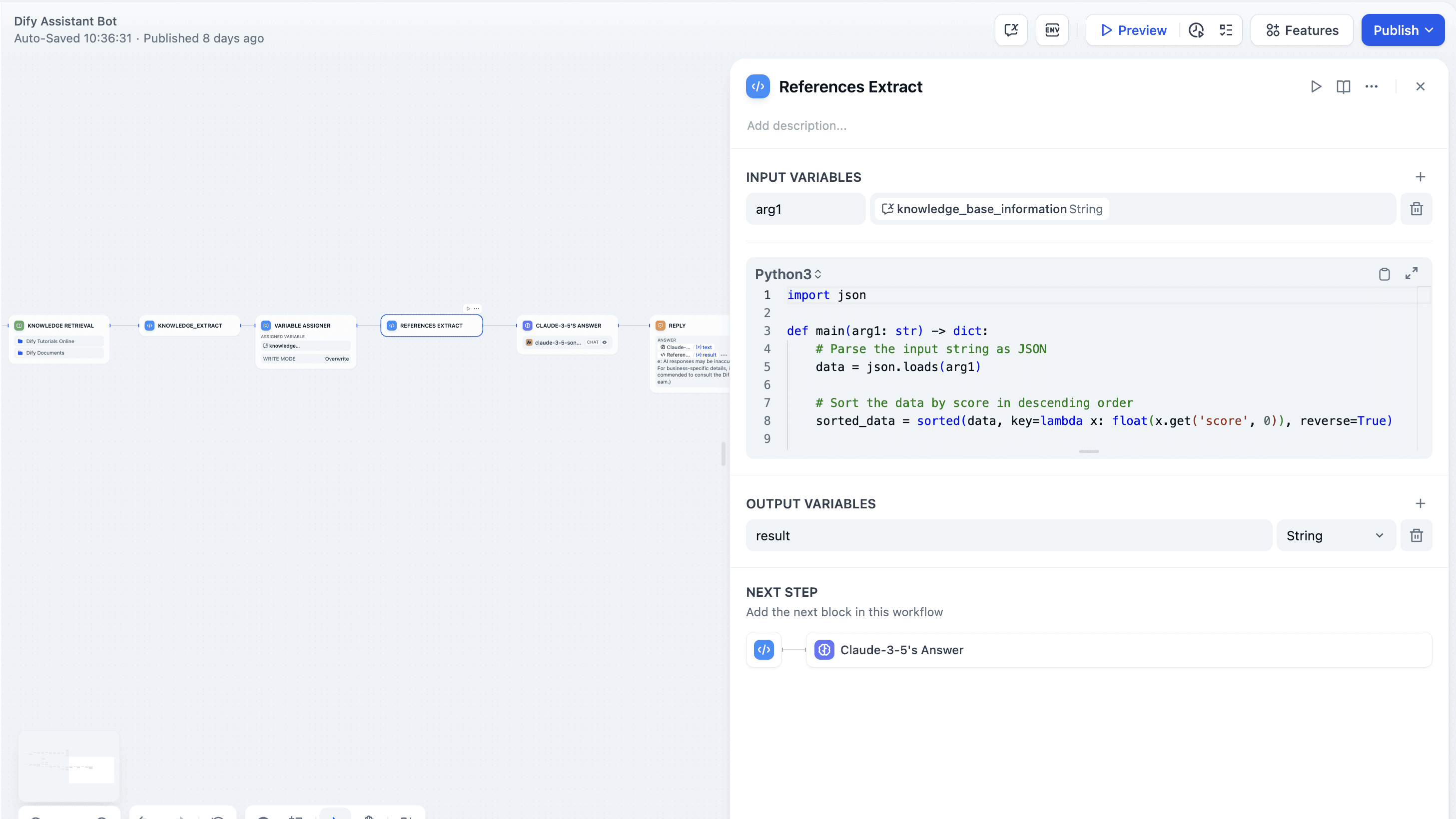
import json
def main(arg1):
result = []
for item in arg1:
metadata = item.get('metadata', {})
extracted_info = {
'document_name': metadata.get('document_name'),
'score': metadata.get('score')
}
result.append(extracted_info)
result_str = json.dumps(result, ensure_ascii=False)
return {"result": result_str}
import json
def main(arg1):
result = []
for item in arg1:
metadata = item.get('metadata', {})
extracted_info = {
'document_name': metadata.get('document_name'),
'score': metadata.get('score')
}
result.append(extracted_info)
result_str = json.dumps(result, ensure_ascii=False)
return {"result": result_str}Sponsor

Related Tutorial
🍃 Nothing Here Now ~
🍃 Nothing Here Now ~
🍃 Nothing Here Now ~
Subscribe to our newsletter 🤩
We regularly list new indie products & makers. Get them in your inbox!
We regularly list new indie products & makers. Get them in your inbox!
We regularly list new indie products & makers. Get them in your inbox!